Week 5 Session 2: BERT#
1. Introduction to BERT#
BERT (Bidirectional Encoder Representations from Transformers) was introduced in 2018, marking a significant milestone in Natural Language Processing (NLP). The BERT paper presented a novel language representation model that outperformed previous models across a wide range of NLP tasks.

Key points about BERT:
It’s a deep bidirectional transformer model
Pre-trained on a vast corpus of unlabeled text
Designed to predict masked words within a sentence and anticipate the subsequent sentence
Can be fine-tuned for various downstream NLP tasks
BERT builds upon two essential ideas:
The Transformer architecture
Unsupervised pre-training
Structure of BERT:
12 (or 24) layers
12 (or 16) attention heads
110 million parameters
No weight sharing across layers
2. The Architecture of BERT#
2.1 Attention Mechanism#
The core component of BERT is the attention mechanism, which allows the model to assign weights to different parts of the input based on their importance for a specific task.
Example: In the sentence “The dog from down the street ran up to me and ___”, to complete the sentence, the model may give more attention to the word “dog” than to the word “street”.
The attention mechanism takes two inputs:
Query: The part of the input we want to focus on
Key: The part of the input we want to compare the query to
The output is a weighted sum of the values of the key, with weights computed by a function of the query and the key.
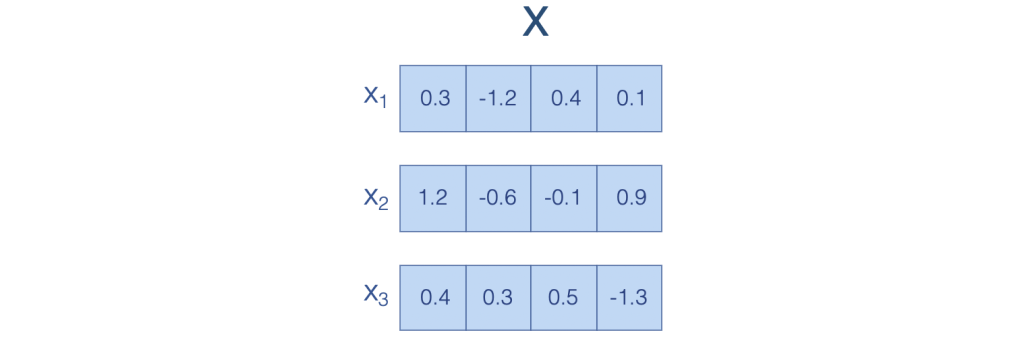
Fig. 1 Sentence vector#
This figure shows how a sequence of words (X) is represented as vectors, where each element (xi) is a value of dimension d.
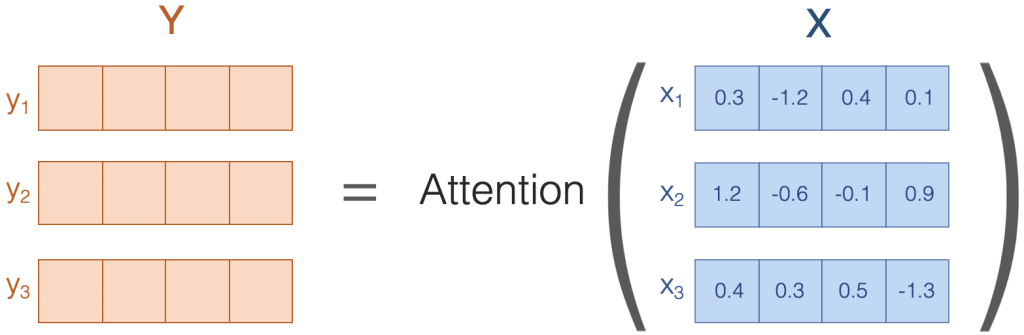
Fig. 2 Sentence input and output#
This figure illustrates how attention transforms the input sequence X into an output sequence Y of the same length, composed of vectors with the same dimension.
2.2 Word Embeddings in BERT#
BERT represents words as vectors (word embeddings) that capture various aspects of their meaning.
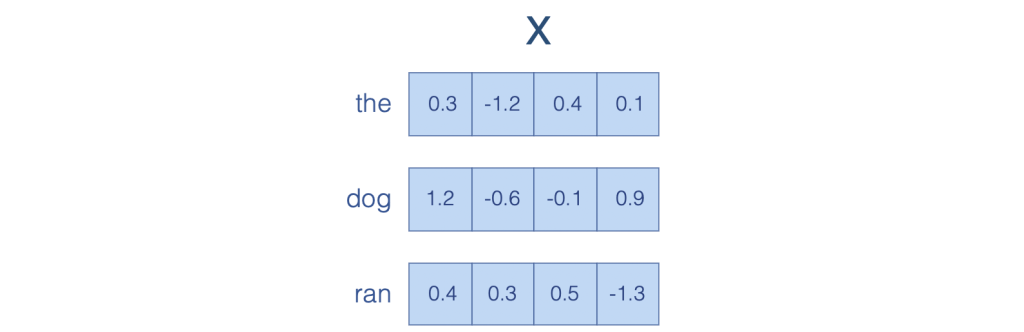
Fig. 3 Word embedding#
This figure shows how a sentence “the dog ran” is represented as a sequence of word embedding vectors.
Word embeddings allow for arithmetic operations on words: Example: cat - kitten ≈ dog - puppy
2.3 Attention Mechanism Simplified#
graph TD
A[Input: the cat ran] --> B[Attention Weights] --> C[Output: cat]
This diagram illustrates a simplified version of the attention mechanism, showing how it focuses on important words in a sentence.
graph LR
A[Input: the cat ran] --> B[Attention Weights: 0.1, 0.8, 0.1] --> C[Output: cat]
This diagram shows the attention mechanism with specific attention weights, demonstrating how the model focuses more on the word “cat” in this example.
3. Deconstructing Attention#
3.1 Queries and Keys#
Attention uses queries and keys to compute weights for each word in the input.
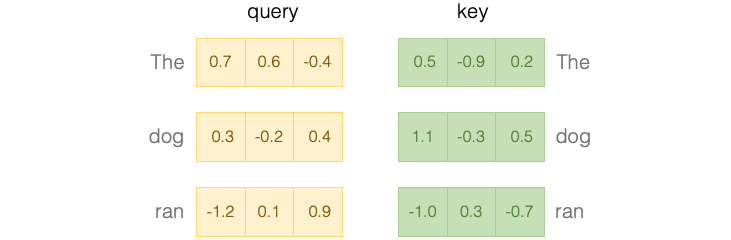
Fig. 4 Attention query and key#
This figure shows how queries and keys are used in the attention mechanism.
The similarity between words is calculated by taking the dot product of their query and key vectors:

Fig. 5 Attention query and key dot product#
The dot product is then transformed into a probability using the softmax function:
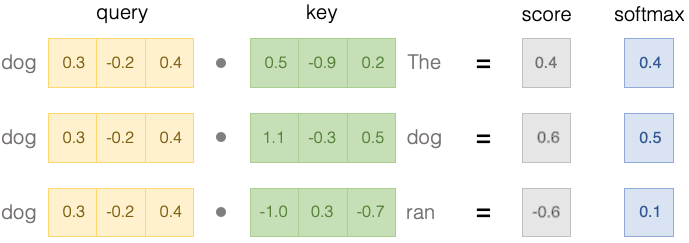
Fig. 6 Attention query and key softmax#
3.2 Neuron View of Attention#
The neuron view provides a detailed look at how attention weights are computed:
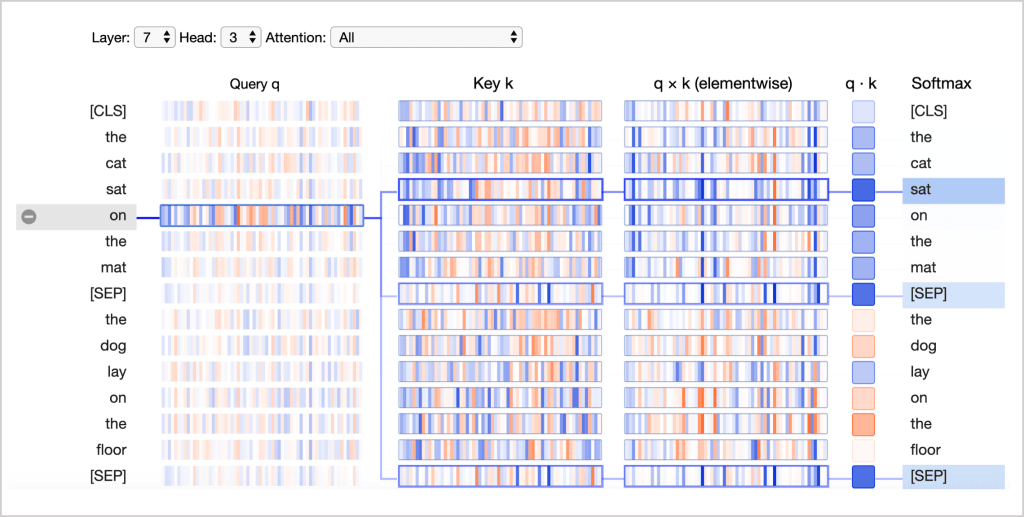
Fig. 7 Neuron view#
This figure breaks down the attention computation process:
Query q: Encodes the word paying attention
Key k: Encodes the word being attended to
q×k (elementwise): Shows how individual elements contribute to the dot product
q·k: The unnormalized attention score
Softmax: Normalizes the attention scores
4. Multi-head Attention#
BERT uses multiple attention mechanisms (heads) operating simultaneously:
Each head represents a distinct attention mechanism
Outputs of all heads are concatenated and fed into a feed-forward neural network
Allows the model to learn a variety of relationships between words
5. Pre-training and Fine-tuning#
BERT uses a two-step training process:
5.1 Pre-training#
During pre-training, BERT is trained on a large corpus of unlabeled text data using two unsupervised learning objectives:
Masked Language Modeling (MLM):
Some words in a sentence are randomly masked
The model is trained to predict the masked words based on context
Forces the model to learn contextual representations of words
Next Sentence Prediction (NSP):
The model is given two sentences
It predicts whether the second sentence follows the first in the original text
Helps the model learn relationships between sentences and capture long-range dependencies
5.2 Fine-tuning#
After pre-training, BERT is fine-tuned on specific NLP tasks using labeled data:
The model is trained for a few additional epochs on task-specific datasets
Pre-trained weights are updated to better capture patterns in the task-specific data
Allows BERT to leverage knowledge from pre-training and adapt to specific tasks
This two-step process enables BERT to achieve state-of-the-art performance across various NLP tasks, such as sentiment analysis, named entity recognition, and question answering.
Conclusion#
BERT represents a significant advancement in NLP, offering a powerful and flexible approach to language understanding. Its use of bidirectional context, attention mechanisms, and the two-step training process allows it to capture complex linguistic patterns and achieve superior performance on a wide range of NLP tasks.